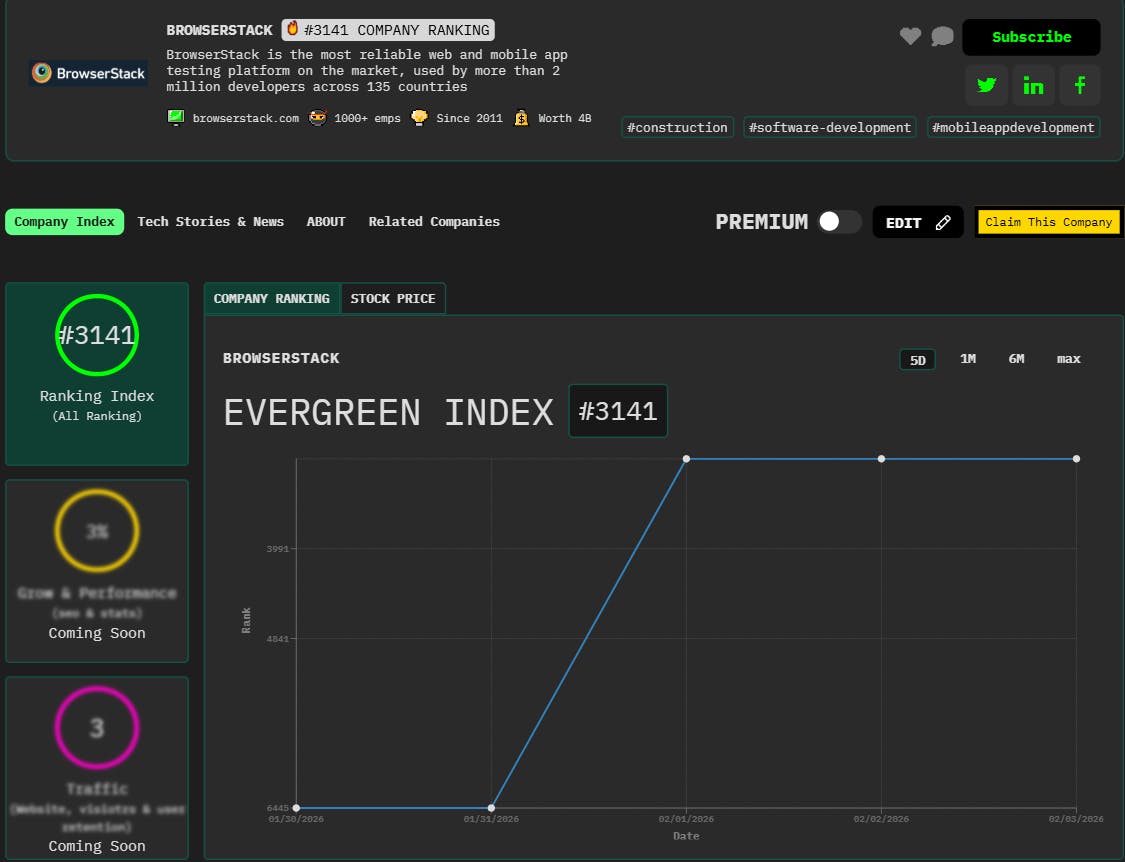
![Tensor Flow - [Technical Documentation]](https://cdn.hackernoon.com/images/undefined-q683u5r.jpeg)
TensorFlow is an open-source machine learning framework developed by Google for numerical computation and building mach
Story's Credibility

![Tensor Flow - [Technical Documentation]](https://hackernoon.imgix.net/images/undefined-q683u5r.jpeg?auto=format&fit=max&w=96)
TensorFlow is an open-source machine learning framework developed by Google for numerical computation and building mach
Story's Credibility
About Author
![Tensor Flow - [Technical Documentation] HackerNoon profile picture](https://hackernoon.imgix.net/images/undefined-q683u5r.jpeg?auto=format&fit=max&w=3840)
TensorFlow is an open-source machine learning framework developed by Google for numerical computation and building mach
COMMENTI