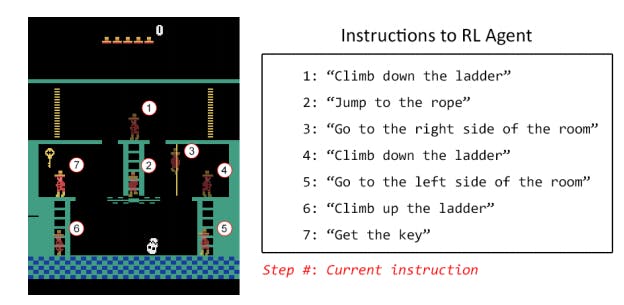
Originally published in ’s . Andreessen Horowitz AI Playbook There are four major ways to train deep networks: , , , and . We’ll explain the intuitions behind each of the these methods. Along the way, we’ll share terms you’ll read in the literature in parentheses and point to more resources for the mathematically inclined. By the way, these categories span both traditional machine learning algorithms and the newer, fancier deep learning algorithms. learning supervised unsupervised semi-supervised reinforcement learning For the math-inclined, see and includes code samples. this Stanford tutorial which covers supervised and unsupervised learning Supervised Learning trains networks using examples where we already know the correct answer. Imagine we are interested in training a to recognize pictures from your photo library that have your parents in them. Here’s the steps we’d take in that hypothetical scenario. Supervised Learning network Step 1: Data Set Creation and Categorization We would start the process by going through your photos (the data set) and identifying all the pictures that have your parents in them, labeling them. We would then take the whole stack of photos and split them into two piles. We would use the first pile to train the network (training data) and the second pile to see how accurate the model is at picking out photos with our parents (validation data). Once the data sets are ready, we’d feed the photos to the model. Mathematically, our goal is for the deep network to find a function whose input is a photo and whose output is a 0 when your parents are not in the photo or 1 when they are. This step is usually called the . In this case we’re training for results that are yes-no, but supervised learning can also be used to output a set of values, rather than just a 0 or 1. For example, we might train a network to output the probability that someone will repay a credit card loan, in which case the output is anywhere between 0 and 100. These tasks are called regressions. categorization task Step 2: Training To continue the process, the model makes a prediction for each photo by following rules (activation function) to decide whether to light up a particular node in the work. The model works from left to right one layer a time — we will ignore more complicated networks for the moment. After the network calculates this for every node in the network, we’ll get to the rightmost node (output node) which lights up or not. Since we already know which pictures have your parents in them, we would be able to tell the model whether its prediction is right or wrong. We would then this information to the network. feed back The algorithm uses this feedback, which is the result of a function that quantifies “how far off from the real answer is from the model’s prediction”. This is called a , also known as , or . The result of the function is then used to modify the strength of connections and biases between nodes in a process called since the information travels “backwards” from the result nodes. cost function objective function utility function fitness function backpropagation We’d repeat this for each of the pictures, and in each case the algorithms try to minimize the cost function. There are a variety of mathematical techniques to use this knowledge of whether the model was right or wrong back into the model, but a very common method is gradient descent. has a good layman’s explanation of how this works. Michael Nielsen which involves calculus and linear algebra (and a friendly demon!). Algobeans adds the math Step 3: Verify Once we’ve processed all the photos from our first stack we will be ready to test the model. We would grab the second stack of photos and use them to see how accurately the trained model can pick up photos of your parents. Steps 2 and 3 would typically be repeated by tweaking various things about the model (hyperparameters), such as how many nodes there are, how many layers there are, which mathematical function to use to decide whether a node lights up, how aggressively to train the weights during the backpropagation phase, and so on. This has a good explanation of the knobs you can turn. Quora answer Step 4: Use Finally, once you have an accurate model, you deploy that model into your application. Your expose the model as an API call, such as , and you can call that method from your software, causing the model to make an inference and giving you the result. ParentsInPicture(photo) We’ll go through this exact process later to write an iPhone application that recognizes business cards. It can be hard (that is, expensive) to get a labeled data set, so you need to make sure the value of the prediction justifies the cost of getting the labeled data and training the model in the first place. For example, getting labeled X-rays of people who might have cancer is expensive, but the value of an accurate model that generates few false positives and few false negatives is obviously very high. Unsupervised Learning is for situations where you have a data set but no labels. Unsupervised learning takes the input set and tries to find patterns in the data, for instance by organizing them into groups (clustering) or finding outliers (anomaly detection). For example: Unsupervised Learning Imagine you are a T-shirt manufacturer, and you have a bunch of people’s body measurements. You’d like a clustering algorithm that groups those measurements into a set of clusters so you can decide how big to make your XS, S, M, L, and XL shirts. You are the CTO of a security startup and you want to find anomalies in the history of network connections between computers: network traffic that looks unusual might help you find an employee downloading all their CRM history because they are about to quit or someone transferring an abnormally large amount of money to a new bank account. If you’re interested in this sort of thing, you’ll like this . survey of unsupervised anomaly detection algorithms You are on the Google Brain team, and you wonder what’s in YouTube videos. This is the very real story of the “YouTube cat finder” research that . In , the Google Brain team in conjunction with Stanford researchers Quoc Le and Andrew Ng describe an algorithm that groups YouTube videos into a bunch of categories, including one that contained cats. They didn’t set out to find cats, but the algorithm automatically grouped videos containing cats (and thousands of other objects from the 22,000 object categories defined in ImageNet) together without any explicit training data. kindled the general public’s enthusiasm for AI this paper Some unsupervised learning techniques you’ll read about in the literature include: Autoencoding Principal components analysis Random forests K-means clustering To learn more about unsupervised learning, try . this Udacity class One of the is an idea from Ian Goodfellow (who was working in Yoshua Bengio’s lab at the time) called “generative adversarial networks” in which we pit two neural networks against each other: one network, called the generator is responsible for generating data designed to try and trick the other network, called the discriminator. This approach is achieving some amazing results, such as AI which can generate photo-realistic pictures from or . most promising recent developments in unsupervised learning text strings hand-drawn sketches Semi-supervised Learning combines a lot of unlabeled data with a small amount of labeled data during the training phase. The trained models that result from this training set can be highly accurate and less expensive to train compared to using all labeled data. Our friend Delip Rao at the AI consulting company , for example, built a solution using semi-supervised learning using just 30 labels per class which got the same accuracy as a model trained using supervised learning which required ~1360 labels per class. This enabled their client to scale their prediction capabilities from 20 categories to 110 categories very quickly. Semi-supervised learning Joostware One intuition behind why using unlabeled data can sometimes help make models more accurate: even if you don’t know the answer, you are learning something about what the possible values are and how often specific values appear. Math fans: try this Xiaojin Zhu’s and the . epic 135-slide tutorial accompanying paper which surveys the literature back in 2008 Reinforcement Learning is for situations where you again don’t have labeled data sets, but you do have a way to telling whether you are getting closer to your goal (reward function). The classic children’s game hotter or colder (a variant of ) is a good illustration of the concept. Your job is to find a hidden object, and your friends will call out whether you are getting “hotter” (closer to) or “colder” (farther from) the object. “Hotter/colder” is the reward function, and the goal of the algorithm is to maximize the reward function. You can think of the reward function is a delayed and sparse form of labeled data: rather than getting a specific “right/wrong” answer with each data point, you’ll get a delayed reaction and only a hint of whether you’re heading in the right direction. Reinforcement learning Huckle Buckle Beanstalk DeepMind describing a system that combines reinforcement learning with deep learning to learned to play a set of Atari video games, some with great success (like Breakout) and others terribly (like Montezuma’s Revenge). published a paper in Nature The Nervana team (now at Intel) published that walks through the techniques in detail. an excellent explanatory blog post A very creative Stanford student project by Russell Kaplan, Christopher Sauer, Alexander Sosa illustrates one of the challenges with reinforcement learning and suggests a clever solution. You’ll see in the DeepMind paper that the algorithms failed to learn how to play Montezuma’s Revenge. The reason for this is that, as the Stanford students describe, “reinforcement learning agents still struggle to learn in environments with sparse rewards.” When you don’t get enough “hotter” or “colder” hints, you have a hard time finding the hidden key. The Stanford students basically taught the system to understand and respond to natural language hints such as “climb down the ladder” or “get the key”, making the system the top-scoring algorithm in the OpenAI gym. Watch a . video of the algorithm in action Watch the video of a reinforcement learning system that . learned to play Super Mario World like a boss Richard Sutton and Andrew Barto . Check out the . wrote the book on Reinforcement Learning draft of the 2nd edition Originally published in ’s . Andreessen Horowitz AI Playbook