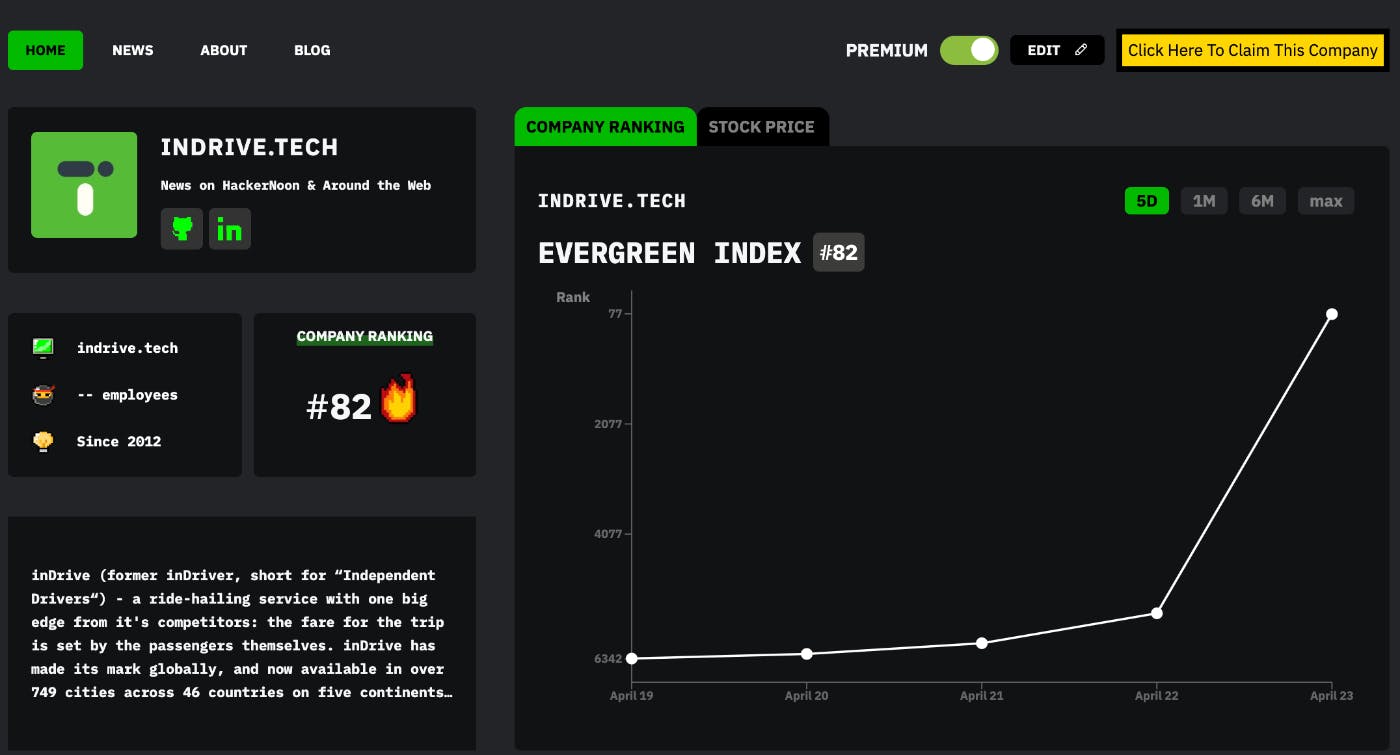
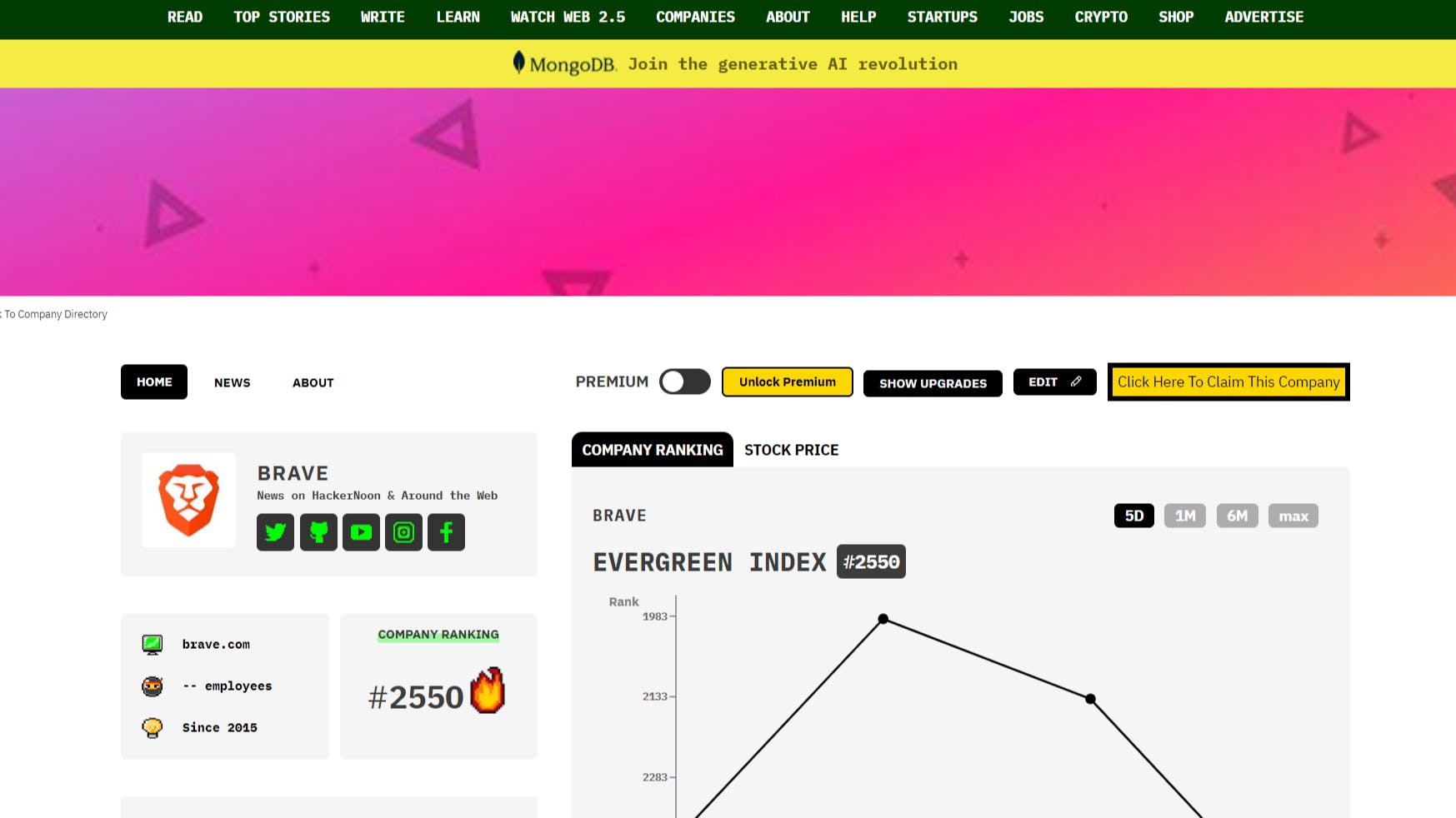
Dev Advocate | Developer & architect | Love learning and passing on what I learned!


Dev Advocate | Developer & architect | Love learning and passing on what I learned!
About Author

Dev Advocate | Developer & architect | Love learning and passing on what I learned!
KOMMENTARER