













































Jan 01, 1970
361 Lesungen
Unimodales Zwischentraining für die multimodale Meme-Sentiment-Klassifizierung
Zu lang; Lesen
Ein neuartiger Ansatz nutzt unimodale Stimmungsdaten, um die multimodale Meme-Stimmungsklassifizierung zu verbessern, den Mangel an gekennzeichneten Daten zu beheben und die Leistung deutlich zu verbessern. Diese Strategie ermöglicht es auch, die Menge der für das Training benötigten gekennzeichneten Meme zu reduzieren, ohne die Leistung des Klassifikators zu beeinträchtigen.Autoren:
(1) Muzhaffar Hazman, University of Galway, Irland;
(2) Susan McKeever, Technological University Dublin, Irland;
(3) Josephine Griffith, University of Galway, Irland.
Linktabelle
Zusammenfassung und Einleitung
Einschränkungen und zukünftige Arbeiten
Schlussfolgerung, Danksagungen und Referenzen
A Hyperparameter und Einstellungen
B-Metrik: Gewichteter F1-Score
E Kontingenztabelle: Baseline vs. Text-STILT
Abstrakt
Internet-Memes bleiben eine anspruchsvolle Form von benutzergenerierten Inhalten für die automatische Stimmungsklassifizierung. Die Verfügbarkeit von beschrifteten Memes ist ein Hindernis für die Entwicklung von Stimmungsklassifizierern für multimodale Memes. Um den Mangel an beschrifteten Memes zu beheben, schlagen wir vor, das Training eines multimodalen Meme-Klassifizierers mit unimodalen (nur Bild- und nur Text-)Daten zu ergänzen. In dieser Arbeit stellen wir eine neuartige Variante des überwachten Zwischentrainings vor, die relativ reichlich mit Stimmungen beschriftete unimodale Daten verwendet. Unsere Ergebnisse zeigen eine statistisch signifikante Leistungsverbesserung durch die Einbeziehung unimodaler Textdaten. Darüber hinaus zeigen wir, dass der Trainingssatz beschrifteter Memes um 40 % reduziert werden kann, ohne die Leistung des nachgelagerten Modells zu beeinträchtigen.
1. Einleitung
Da Internet-Memes (oder einfach „Memes“) in digitalen Communities weltweit immer beliebter und alltäglicher werden, hat das Forschungsinteresse zugenommen, Aufgaben zur Klassifizierung natürlicher Sprache, wie Stimmungsklassifizierung, Hassrede-Erkennung und Sarkasmus-Erkennung, auf diese multimodalen Ausdruckseinheiten auszudehnen. Moderne multimodale Meme-Stimmungsklassifizierer schneiden jedoch deutlich schlechter ab als moderne Text- und Bildstimmungsklassifizierer. Ohne genaue und zuverlässige Methoden zur Identifizierung der Stimmung multimodaler Memes müssen Methoden zur Stimmungsanalyse in sozialen Medien Meinungen, die über Memes ausgedrückt werden, entweder ignorieren oder ungenau ableiten. Da Memes weiterhin eine tragende Säule im Online-Diskurs sind, ist unsere
Die Fähigkeit, die von ihnen vermittelte Bedeutung zu erschließen, wird zunehmend relevanter (Sharma et al., 2020; Mishra et al., 2023).
Es bleibt eine Herausforderung, bei Memes eine ähnliche Leistung bei der Klassifizierung von Stimmungen zu erreichen wie bei unimodalen Inhalten. Zusätzlich zu ihrer multimodalen Natur müssen multimodale Meme-Klassifikatoren Stimmungen aus kulturspezifischen Eingaben erkennen, die kurze Texte, kulturelle Referenzen und visuelle Symbolik umfassen (Nissenbaum und Shifman, 2017). Obwohl verschiedene Ansätze verwendet wurden, um Informationen aus jeder Modalität (Text und Bild) zu extrahieren, haben neuere Arbeiten hervorgehoben, dass Meme-Klassifikatoren auch die verschiedenen Formen der Interaktion zwischen diesen beiden Modalitäten erkennen müssen (Zhu, 2020; Shang et al., 2021; Hazman et al., 2023).
Aktuelle Ansätze zum Trainieren von Meme-Klassifikatoren sind auf Datensätze mit gekennzeichneten Memen angewiesen (Kiela et al., 2020; Sharma et al., 2020; Suryawanshi et al., 2020; Patwa et al., 2022; Mishra et al., 2023), die genügend Beispiele enthalten, um Klassifikatoren zu trainieren, relevante Merkmale aus jeder Modalität und relevante modalübergreifende Interaktionen zu extrahieren. Im Verhältnis zur Komplexität der Aufgabe stellt die aktuelle Verfügbarkeit gekennzeichneter Meme immer noch ein Problem dar, da viele aktuelle Arbeiten mehr Daten erfordern (Zhu, 2020; Kiela et al., 2020; Sharma et al., 2022).
Schlimmer noch, Meme sind schwer zu benennen. Die Komplexität und Kulturabhängigkeit von Memen
(Gal et al., 2016) verursachen das Problem der subjektiven Wahrnehmung (Sharma et al., 2020), bei dem die unterschiedliche Vertrautheit und emotionale Reaktion auf den Inhalt eines Memes bei jedem Annotator zu unterschiedlichen Ground-Truth-Beschriftungen führt. Zweitens enthalten Memes oft urheberrechtlich geschützte visuelle Elemente aus anderen populären Medien (Laineste und Voolaid, 2017), was bei der Veröffentlichung von Datensätzen Bedenken aufwirft. Dies erforderte von Kiela et al. (2020), jedes Meme in ihrem Datensatz manuell mithilfe lizenzierter Bilder zu rekonstruieren, was den Annotationsaufwand erheblich erhöhte. Darüber hinaus tauchen die visuellen Elemente, aus denen ein bestimmtes Meme besteht, oft als plötzlicher Trend auf, der sich schnell in Online-Communitys verbreitet (Bauckhage, 2011; Shifman, 2014) und schnell neue semantisch reiche visuelle Symbole in den allgemeinen Meme-Jargon einführt, die zuvor wenig Bedeutung hatten (Segev et al., 2015). Zusammengenommen machen diese Eigenschaften die Beschriftung von Memes besonders herausfordernd und kostspielig.
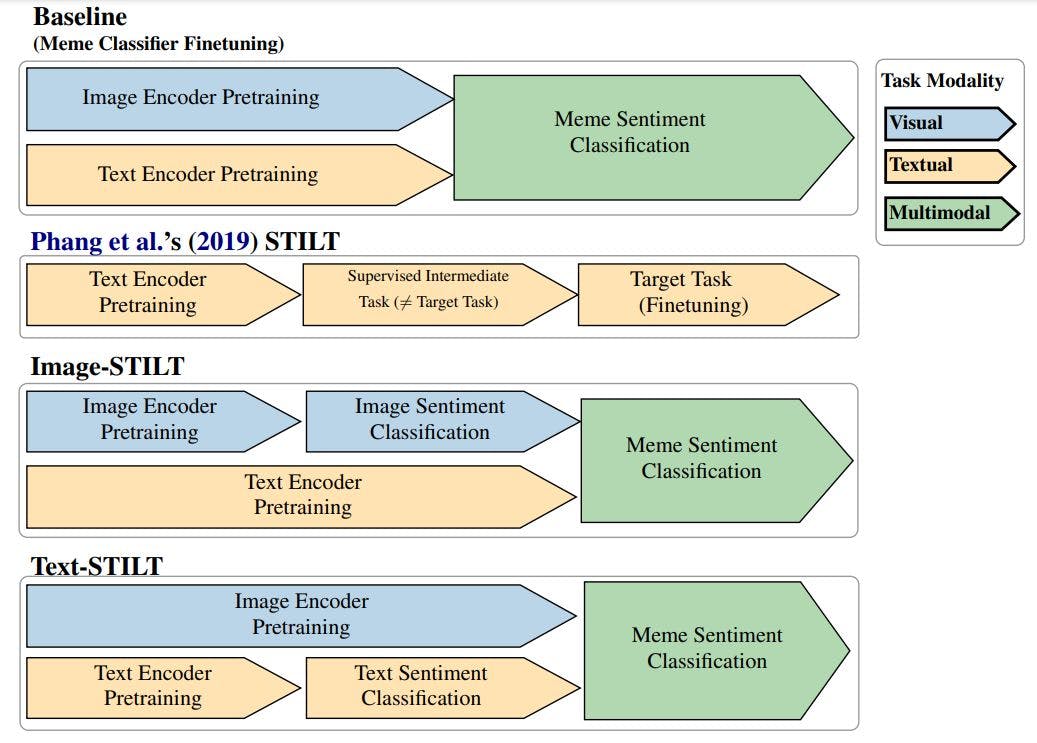
Auf der Suche nach dateneffizienteren Methoden zum Trainieren von Meme-Sentiment-Klassifikatoren versucht unsere Arbeit, die relativ reichlich vorhandenen unimodalen Sentiment-gelabelten Daten zu nutzen, d. h. Sentiment-Analyse-Datensätze mit reinen Bild- und reinen Textbeispielen. Dazu verwenden wir Phang et al.s (2019) Supplementary Training on Intermediate Labeleddata Tasks (STILT), das die niedrige Leistung behebt, die häufig beim Feintuning vortrainierter Textencoder für datenarme Natural Language Understanding (NLU)-Aufgaben auftritt. Der STILT-Ansatz von Phang et al. umfasst drei Schritte:
1. Laden Sie vortrainierte Gewichte in ein Klassifikatormodell.
2. Optimieren Sie das Modell anhand einer überwachten Lernaufgabe, für die Daten leicht verfügbar sind (die Zwischenaufgabe).
3. Optimieren Sie das Modell anhand einer datenarmen Aufgabe (der Zielaufgabe), die sich von der Zwischenaufgabe unterscheidet.
STILT hat sich als leistungssteigernd für verschiedene Modelle bei einer Vielzahl von reinen Text-Zielaufgaben erwiesen (Poth et al., 2021; Wang et al., 2019). Darüber hinaus stellten Pruksachatkun et al. (2020) fest, dass STILT besonders effektiv bei Zielaufgaben in NLU mit kleineren Datensätzen ist, z. B. WiC (Pilehvar und Camacho-Collados, 2019) und BoolQ (Clark et al., 2019). Sie zeigten jedoch auch, dass die Leistungsvorteile dieses Ansatzes inkonsistent sind und von der Auswahl geeigneter Zwischenaufgaben für jede gegebene Zielaufgabe abhängen. In einigen Fällen erwies sich das Zwischentraining als nachteilig für die Leistung bei Zielaufgaben; was Pruksachatkun et al. (2020) auf Unterschiede zwischen den erforderlichen „syntaktischen und semantischen Fähigkeiten“ zurückführten, die für jedes Zwischen- und Zielaufgabenpaar erforderlich sind. STILT wurde jedoch noch nicht in einer Konfiguration getestet, in der Zwischen- und Zielaufgaben unterschiedliche Eingabemodalitäten haben.
Obwohl die isolierte Betrachtung des Textes oder Bildes eines Memes nicht dessen gesamte Bedeutung vermittelt (Kiela et al., 2020), vermuten wir, dass unimodale Sentimentdaten dabei helfen können, Fähigkeiten zu entwickeln, die für die Wahrnehmung der Stimmung von Memes relevant sind. Indem wir eine neuartige Variante von STILT vorschlagen, die unimodale Sentimentanalysedaten als Zwischenaufgabe beim Training eines multimodalen Meme-Sentiment-Klassifikators verwendet, beantworten wir die folgenden Fragen:
RQ1 : Verbessert die Ergänzung des Trainings eines multimodalen Meme-Klassifikators mit unimodalen Sentimentdaten dessen Leistung erheblich?
Wir haben unseren vorgeschlagenen Ansatz separat mit 3-Klassen-Sentimentdaten getestet, die nur aus Bildern und nur aus Text bestehen (wodurch jeweils Image-STILT und Text-STILT erstellt wurden), wie in Abbildung 1 dargestellt. Wenn sich einer der beiden Ansätze als effektiv erweist, beantworten wir zusätzlich:
RQ2 : Inwieweit können wir mit unimodalem STILT die Menge der gekennzeichneten Meme reduzieren und gleichzeitig die Leistung eines Meme-Sentiment-Klassifikators beibehalten?
Dieses Dokument ist auf Arxiv unter der CC 4.0-Lizenz verfügbar .
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
Hängeetiketten
Languages
ÄHNLICHE BEITRÄGE
Android vs Apple: HackerNoon Debates
#slogging



